 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIESR:Efficient MCTS-Based Modular Reasoning for Text-to-SQL with Large Language Models
Feb 05, 2026Text-to-SQL is a key natural language processing task that maps natural language questions to SQL queries, enabling intuitive interaction with web-based databases. Although current methods perform well on benchmarks like BIRD and Spider, they struggle with complex reasoning, domain knowledge, and hypothetical queries, and remain costly in enterprise deployment. To address these issues, we propose a framework named IESR(Information Enhanced Structured Reasoning) for lightweight large language models: (i) leverages LLMs for key information understanding and schema linking, and decoupling mathematical computation and SQL generation, (ii) integrates a multi-path reasoning mechanism based on Monte Carlo Tree Search (MCTS) with majority voting, and (iii) introduces a trajectory consistency verification module with a discriminator model to ensure accuracy and consistency. Experimental results demonstrate that IESR achieves state-of-the-art performance on the complex reasoning benchmark LogicCat (24.28 EX) and the Archer dataset (37.28 EX) using only compact lightweight models without fine-tuning. Furthermore, our analysis reveals that current coder models exhibit notable biases and deficiencies in physical knowledge, mathematical computation, and common-sense reasoning, highlighting important directions for future research. We released code at https://github.com/Ffunkytao/IESR-SLM.
LogicCat: A Chain-of-Thought Text-to-SQL Benchmark for Multi-Domain Reasoning Challenges
May 24, 2025Text-to-SQL is a fundamental task in natural language processing that seeks to translate natural language questions into meaningful and executable SQL queries. While existing datasets are extensive and primarily focus on business scenarios and operational logic, they frequently lack coverage of domain-specific knowledge and complex mathematical reasoning. To address this gap, we present a novel dataset tailored for complex reasoning and chain-of-thought analysis in SQL inference, encompassing physical, arithmetic, commonsense, and hypothetical reasoning. The dataset consists of 4,038 English questions, each paired with a unique SQL query and accompanied by 12,114 step-by-step reasoning annotations, spanning 45 databases across diverse domains. Experimental results demonstrate that LogicCat substantially increases the difficulty for state-of-the-art models, with the highest execution accuracy reaching only 14.96%. Incorporating our chain-of-thought annotations boosts performance to 33.96%. Benchmarking leading public methods on Spider and BIRD further underscores the unique challenges presented by LogicCat, highlighting the significant opportunities for advancing research in robust, reasoning-driven text-to-SQL systems. We have released our dataset code at https://github.com/Ffunkytao/LogicCat.
JOLT-SQL: Joint Loss Tuning of Text-to-SQL with Confusion-aware Noisy Schema Sampling
May 20, 2025



Text-to-SQL, which maps natural language to SQL queries, has benefited greatly from recent advances in Large Language Models (LLMs). While LLMs offer various paradigms for this task, including prompting and supervised fine-tuning (SFT), SFT approaches still face challenges such as complex multi-stage pipelines and poor robustness to noisy schema information. To address these limitations, we present JOLT-SQL, a streamlined single-stage SFT framework that jointly optimizes schema linking and SQL generation via a unified loss. JOLT-SQL employs discriminative schema linking, enhanced by local bidirectional attention, alongside a confusion-aware noisy schema sampling strategy with selective attention to improve robustness under noisy schema conditions. Experiments on the Spider and BIRD benchmarks demonstrate that JOLT-SQL achieves state-of-the-art execution accuracy among comparable-size open-source models, while significantly improving both training and inference efficiency.
CBLUE: A Chinese Biomedical Language Understanding Evaluation Benchmark
Jul 06, 2021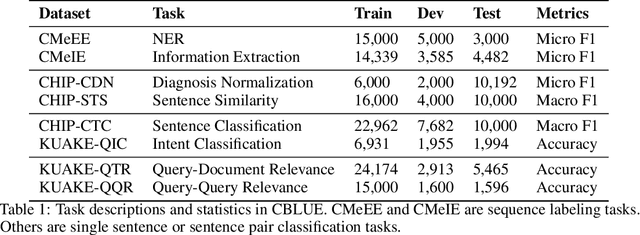
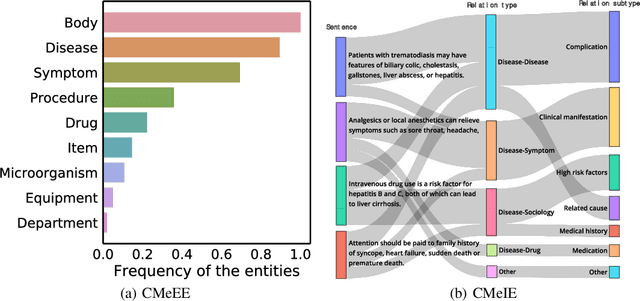
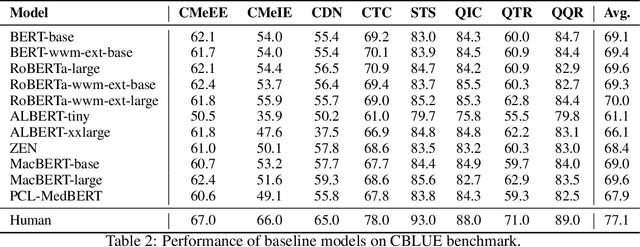
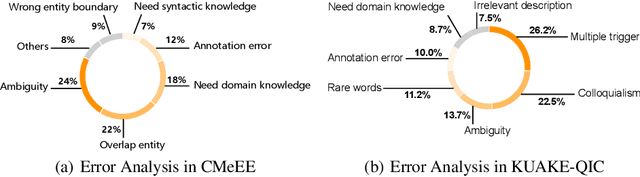
Artificial Intelligence (AI), along with the recent progress in biomedical language understanding, is gradually changing medical practice. With the development of biomedical language understanding benchmarks, AI applications are widely used in the medical field. However, most benchmarks are limited to English, which makes it challenging to replicate many of the successes in English for other languages. To facilitate research in this direction, we collect real-world biomedical data and present the first Chinese Biomedical Language Understanding Evaluation (CBLUE) benchmark: a collection of natural language understanding tasks including named entity recognition, information extraction, clinical diagnosis normalization, single-sentence/sentence-pair classification, and an associated online platform for model evaluation, comparison, and analysis. To establish evaluation on these tasks, we report empirical results with the current 11 pre-trained Chinese models, and experimental results show that state-of-the-art neural models perform by far worse than the human ceiling. Our benchmark is released at \url{https://tianchi.aliyun.com/dataset/dataDetail?dataId=95414&lang=en-us}.